Basic HTML Version


325
e il DNA
non codificante
Il progetto genoma umano
B
I
O
T
E
C
H
Il progetto di mappare l’intero genoma umano
venne lanciato negli anni Ottanta del
Novecento dal premio Nobel James Watson,
scopritore con Francis Crick della struttura a
doppia elica del DNA. Lo
Human Genome
Project
(Progetto Genoma Umano, PGU) partì
ufficialmente nel 1990, con l’obiettivo di deci-
frare entro il 2005 gli oltre tre miliardi di basi
che compongono il nostro patrimonio geneti-
co e identificarne tutti i geni. Si trattava di un
progetto internazionale di ricerca che coinvol-
geva un migliaio di scienziati di circa cinquan-
ta Paesi, tra cui l’Italia.
Scopo principale del PGU era fornire alla comu-
nità scientifica una sequenza completa del DNA
umano, disponibile senza restrizioni: una risorsa
importantissima per lo studio dei meccanismi alla
base del funzionamento del nostro organismo e
delle malattie genetiche. Per tale motivo, le linee
guida del Progetto prevedevano che tutti i labo-
ratori partecipanti riversassero i dati raccolti nei
database pubblici entro 24 ore dalla scoperta.
Geni “pubblici”
Un fortissimo impulso al PGU venne dalla con-
correnza di una società privata, la Celera Geno-
mics Corporation, fondata nel 1998 dallo scien-
ziato imprenditore Craig Venter e quotata in Bor-
sa. La Celera avviò in parallelo al PGU un lavo-
ro di sequenziamento del genoma di
Homo sa-
piens
con lo scopo dichiarato di creare una ban-
ca dati utilizzabile solo a pagamento. Tale ap-
proccio rese Venter molto impopolare nella co-
munità scientifica e costituì un nuovo stimolo
per i numerosi gruppi che partecipavano al
PGU. Ne nacque una vera e propria gara senza
esclusione di colpi – entrambi i contendenti si
accusarono di aver copiato i dati resi disponibi-
li dall’altro – finché nel 2000 Venter annunciò
di aver sequenziato l’intero genoma umano. Il
consorzio internazionale, costretto a stringere i
tempi, annunciò il sequenziamento nel 2003.
I risultati pubblicati dalle due équipe risultaro-
no molto simili nel contenuto. La principale
differenza consisteva nel fatto che il genoma
sequenziato da Celera era stato ottenuto a
partire da cinque soli individui (uno dei quali
Venter stesso), mentre il PGU si era servito di
sequenze genomiche provenienti da individui
di numerose parti del mondo, elaborate per
ottenere un’unica sequenza, rappresentativa
del patrimonio genetico umano. Anche per
tale motivo, il genoma a pagamento di Celera
ebbe poco successo rispetto a quello del PGU.
Una volta disponibile la sequenza completa
del DNA umano, restava ancora il difficile
compito di capirne il significato: quanti sono i
geni? Come funzionano? Qual è il ruolo del
DNA non codificante?
Geni “privati”
Una delle principali sorprese è stata il ridotto
numero dei geni trovati: circa 25000 invece
dei 100000 previsti, poco più del doppio di
quelli della
Drosophila melanogaster
, il
moscerino della frutta (figura
A
).
Oggi sappiamo che i geni veri e propri costitui-
scono soltanto il 3% del materiale ereditario
umano. Il resto è costituito da sequenze di
DNA non codificanti (
paragrafo 7
). Il DNA
non codificante ha probabilmente un impor-
tante significato evolutivo anche se il suo
ruolo resta ancora da chiarire.
Parallelamente al PGU sono nati molti altri
Progetti Genoma, alcuni dedicati a specie di
interesse per l’uomo: come alcune piante e
batteri, il topo e lo scimpanzé. Oggi il sequen-
ziamento dell’intero genoma o di parti di esso
è uno stumento di routine nei laboratori di
biologia molecolare (
sezione M
).
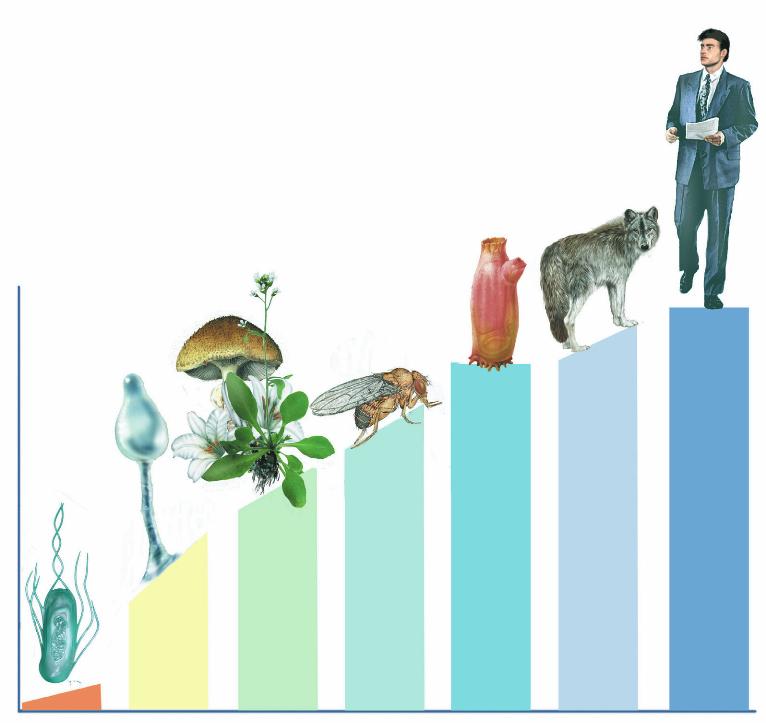
Figura A
La principale differenza tra il genoma
umano e quello di altre specie non sta nel
numero dei geni, ma nella quantità di
DNA non codificante (pb = paia di basi).
Escherichia coli
4,7 milioni pb
4400 geni
procarioti
eucarioti
unicellulari
funghi
e piante
invertebrati
cordati
vertebrati
uomo
Dictyostelium
discoideum
34 milioni pb
12500 geni
Arabidopsis thaliana
115 milioni pb
28000 geni
Drosophila
melanogaster
123 milioni pb
13400 geni
Ciona intestinalis
160 milioni pb
15000 geni
Canis lupus
2,4 miliardi pb
19000 geni
Homo sapiens
3 miliardi pb
25000 geni
DNA non codificate (%)